项目总体流程
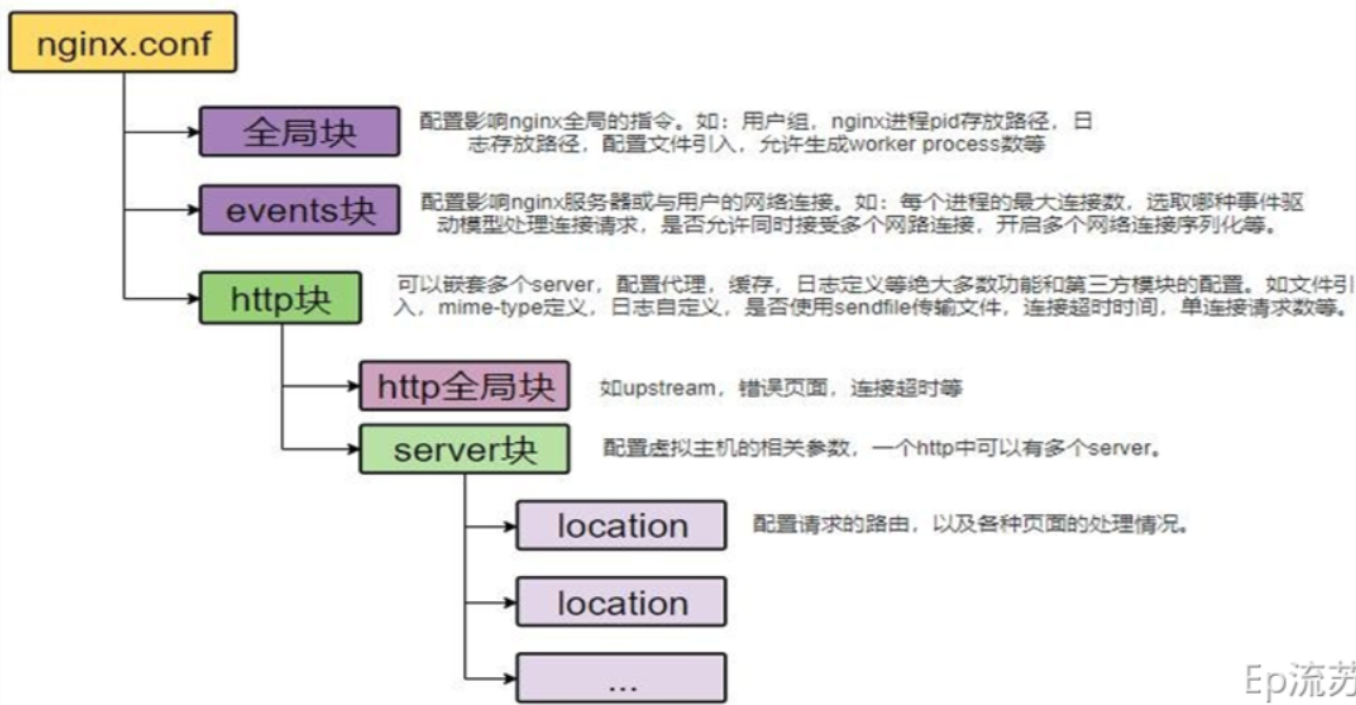
通过Nginx搭建域名
首先使用Nginx搭建了一个域名访问环境。
为什么需要要使用nginx搭建这个域名访问呢?
首先从正向代理和反向代理来看:
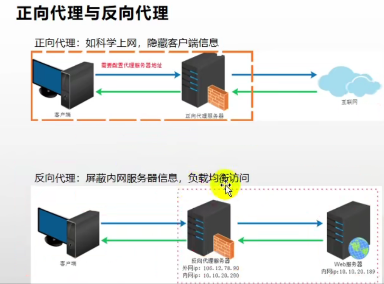
- 正向代理:就是客户端在访问某些网址的时候,通过代理服务器进行访问,这样就隐藏了自己的信息进行访问,保证客户端信息的安全
- 反向代理:就是搭建项目环境的时候,通过一个代理服务器,屏蔽内网的服务器信息,对外保暴露的是代理服务器的信息,这样别人通过访问代理服务器,然后代理服务器转发请求到内网服务器上进行访问
为什么使用Nginx搭配网关进行搭建?
因为如果直接使用Nginx路由到端口上,那么如果在集群模式下,一个服务对应多个端口,就需要配置多个端口信息,这样很麻烦,所以通过网关进行路由,这样即使在集群环境下搭建的微服务,我们只需要路由到网管,然后让网关进行服务的调用即可
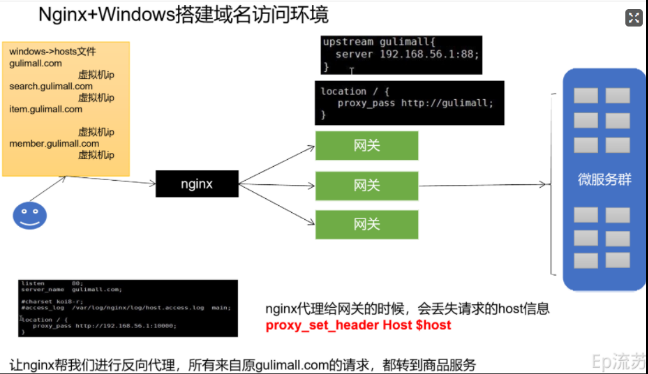
如何搭建的?
- 首先安装Nginx,然后修改Nginx的配置文件,因为要映射到本机器上的网关上,所以首先配置一个上游服务器地址请求转发到网关上,配置了这个地址之后,再配置Nginx的代理地址,这个代理地址指向的是上游服务器的地址,那么通过这个代理地址,我们每次访问Nginx,都会访问它的80默认端口,然后Nginx会通过代理地址转发到上游服务器地址,再通过上游服务器地址访问网关。
遇到的问题:一开始在阿里云上部署的Nginx,然后通过本地的域名访问阿里云上的Nginx,发现Nginx一直无法访问本地服务器,一直报服务器错误,然后网上查了一下说,本地服务器需要备案才能访问内网,然后我去阿里云上看了一下需要备案,还要搞好多东西,我心里想着就是做一个项目,没想到这么麻烦,就没有备案,在网上查了好多方法,然后看到一个可以内网穿透的软件,通过那个软件可以代理一个内网穿透的地址,这个地址可以访问内网,然后我就花了十来块钱买了一个月,本来心里想着这下没问题了吧,但是后面使用动静分离那一块,一直出现静态资源无法访问,最终,没办法,就在本地安装了一个Nginx,好了一切问题都解决了,但是这个代理好像没什么太大意义!!!
通过认证服务完成了社交登陆功能(验证码,接口防刷)
首先是注册功能,这里使用了阿里云的验证码进行验证,验证成功之后就可以进行注册了,但是因为验证码的条数是要钱的,所以如果一直被别人刷的话,那验证码的条数就浪费了,因此做了一个接口防刷的功能
如何实现接口防刷的?
- 这里使用到了Redis,每次发送短信验证码请求的时候,就会将这个手机号和验证码绑定在一起,然后一起存到redis中,并且设置过期时间为一分钟,如果下次相同的手机号再次发送短信验证,首先会将这个手机号获取,然后通过手机号查询redis中是否存在该手机号,如果存在,那么就直接返回错误信息,如果没有,那么就输入验证码进行注册功能。
除了使用这个方法进行防刷,你还了解其他的吗?
- 对单个手机号进行请求限制,如果这个手机号在规定时间段里发送的次数过多,就可以限制这个手机号此时间段内不能再发请求了
- 对单个Ip进行限制,这样虽然可以防止在一个ip地址下,多个手机号被刷的次数,但是同样的,因为一个小区可能都使用的一个ip地址,如果此时别人也在使用注册功能,那么将是一个很大的问题
- 网关进行控制,把当前时间段,同一个手机号多次恶意注册的请求拦截
如何实现密码的加密的?
- 密码加密主要是保证用户信息的安全性,即使用户信息不小心暴露出去,也不能通过账号和验证码进行登录。实现密码的加密方式主要是使用MD5进行加密的,因为在网上看到了很多对MD5进行破解的软件,因此这里我使用了MD5盐值加密,使用这个会随机的在密码的基础上加一个字符串,这样就能保证密码永远对应的都是不同MD5值,有更高的安全性
社交登录功能
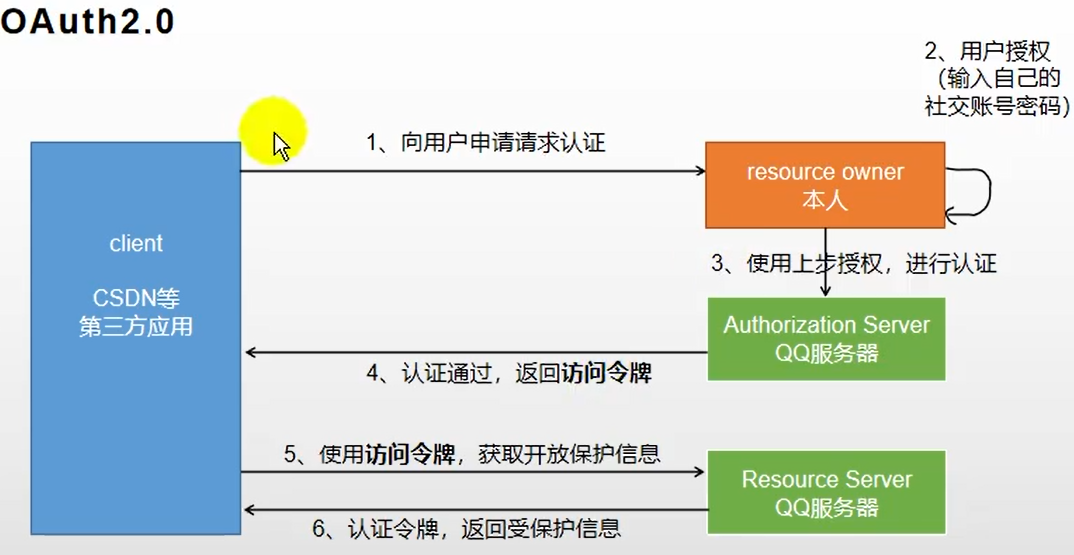
什么是OAuth2.0
- OAuth2.0就是开放授权,意思就是用户可以通过给第三方授权,然后获取自己的相关信息,而不需要将用户的账户和密码提供给第三方网站。
说说OAuth2.0的工作原理?
如何实现社交登陆的?
这里首先是在微博的开放平台注册了一个个人应用,然后这个应用对应的域名就是本机服务的域名,注册成功。我们可以通过第三方的授权认证登录微博账户,然后通过这个微博注册的应用返回给我们该用户的相关信息,并且在登录的时候会判断这个用户信息是否存在,如果不存在则需要存储当前新用户,如果存在那么就登陆成功。
存储的数据具体流程
前端用户登录了第三方提供的登录地址,然后会返回一个code,然后通过code换取一个token,然后因为token过一段时间会变,所以得给token设置过期时间,然后不变的是uid,通过uid来识别不同的用户信息。
Session共享问题
session的原理?

- 首先用户第一次访问服务器进行登录,登陆成功之后,就会将用户信息保存在session中,然后session会将sessionId返回给浏览器,浏览器就会将这个sessionId存在cookie中,这样,下一次访问页面的时候会带上cookie进行访问。浏览器关闭,清除回话cookie,那么下一次再进来,就需要重新登录
session如果在集群环境下会出现什么问题?
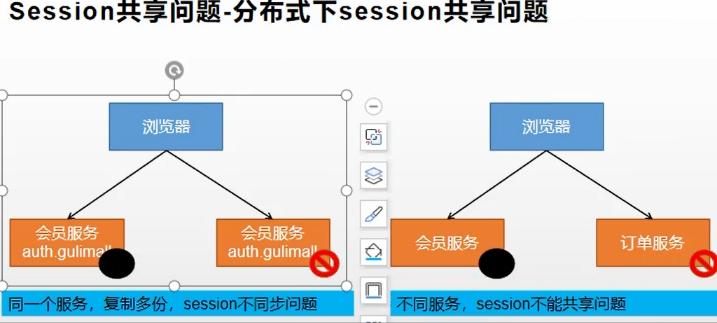
- 如果是在同一个域名,但是不同服务的情况下:
- 在这种情况下,如果浏览器第一次访问当了第一个服务器,那么会在该服务器存储session,并且返回sessionId存储在浏览器中,但是如果浏览器下一次访问的时候,通过负载均衡直接转到另一个服务器上,那么这个时候带上之前的cookie显然是不能进行访问的。
- 如果是在不同域名,不同服务下,session是不能共享的
如何解决这个session不能共享的问题呢???



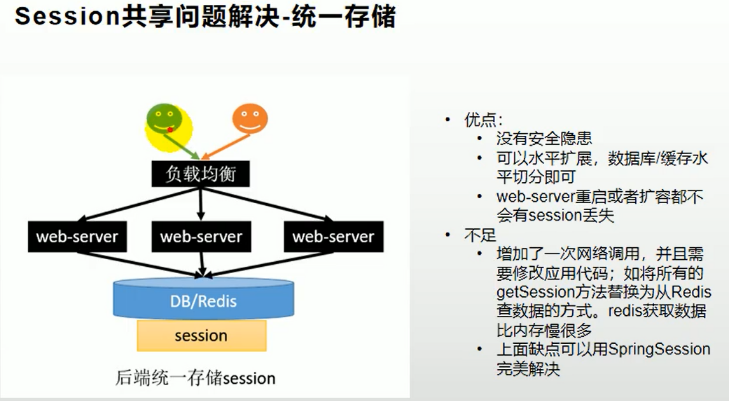
通过Spring Session解决了session不能共享的问题
是怎么解决的呢?
首先导入SpringSession的依赖,然后这里在配置文件中指定存储类型为redis,然后写一个session配置类,主要用于放大作用域和解决序列化问题。解决的流程就是,将登录的用户的session通过redis进行保存,这样以后用户在访问页面的时候,不管访问哪个服务器,服务器都可以直接从redis中找出对应的session与之匹配,然后进行访问
SpringSession的核心原理是什么?
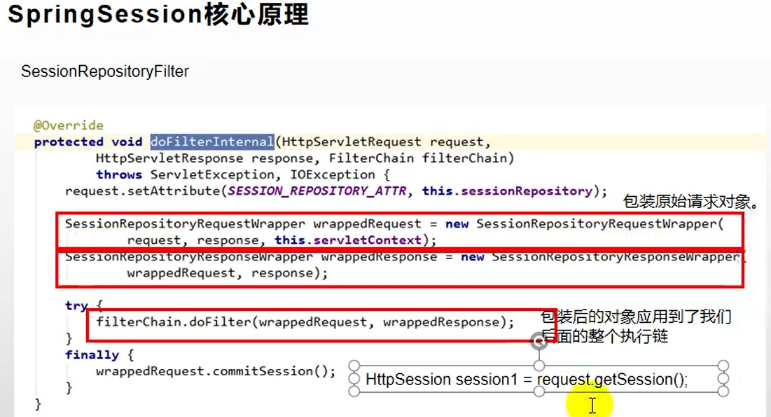

- 它的核心原理有两个重要的点:
- 第一个:给容器中添加了一个SessionRepository的组件,这个组件主要的作用是让redis操作session,相当于redis的Dao
- 第二个:SessionRepositoryFilter,存储过滤器,这个过滤器在创建的时候就会自动的从容器中获取SessionRepository,最重要的就是它里面的doFilter方法,这个方法将原生的request和responce都包装成了Wrapper类型的request和response,然后后续我们的操作中获取session中的信息,都是从SessionRepository中获取而不是在原生的服务器中获取。
- 装饰者模式(责任链模式)
- 它的核心原理有两个重要的点:
使用Redis做缓存提高性能
- 使用缓存存在哪些问题呢?
- 缓存穿透
- 缓存击穿
- 缓存雪崩
- 缓存穿透



分布式锁?怎么实现的?
实现?
先拿setnx来争抢锁,抢到之后,再用expire给锁加一个过期时间防止锁忘记了释放。
当然,因为在设置锁和释放锁的过程中,可能此时服务崩溃,或者其他的一些原因导致系统无法运行,这时候可能无法释放锁,或者业务逻辑执行完成,但是锁没有释放,那么这时候就需要使用redis提供的lua脚本进行实现。
为什么使用分布式锁?解决了什么问题?
在集群环境下,如果使用的都是本地锁,那么如果很多请求进来,每个服务都查询redis,里面都没有数据,那么他们就会针对每个服务都发送查询数据库的命令,这样就造成了很多不必要的查询,因此需要使用分布式锁,所有的请求进来,会首先抢占分布式锁,如果有一个线程抢占成功,那么就通过这一个线程来查询数据库,然后将查询到的数据存到redis中,这样就避免了多个线程,多次查询数据库的操作,造成不必要的资源浪费。
看门狗机制?
如果我们设置了锁的过期时间,那么程序不管是否运行完成,时间一过,锁就过期了,那么别的线程就会抢占锁。但是如果我们不设置过期时间,那么就会触发看门狗机制,看门狗会默认的设置为30s,而且会有一个自动续期的功能,只要时间超过默认时间的三分之一,就会进行一次续期操作
接口幂等性
- 什么是接口幂等?
- 接口幂等就是,比如我们在进行一个提交操作的时候,这时候如果因为网络延迟,我们点了多次提交,然后就会出现多次重复提交的问题,这样可能我们自身只需要一次提交,但是却提交了很多次,这就是接口幂等
- 哪些情况需要防止接口幂等
- 用户多次点击提交按钮
- 用户页面回退,再次点击提交
- 微服务互相调用,因为网络或者别的原因调用失败,使用feign的失败重试机制
- 其他业务…
- 怎么解决接口幂等性?
- Token(令牌)机制
- 用户在提交请求的时候,首先会输入验证码,然后请求会将验证码一起携带传到服务器,服务器会根据传过来的验证码,和存在于redis中的验证码作比较,如果存在,那么就表示请求是第一次进来,如果不存在则表示请求是重复请求。
- 存在哪些危险性呢?
- 验证完成之后,是先删除token再执行业务逻辑,还是先执行业务逻辑再删除呢?
- 先删除token,可能业务还没有执行完成,但是服务器中断,导致这次请求调用失败
- 后删除token,可能业务完成了,但是token没来的及删除,服务器中断,导致下一次请求又会重新执行一次业务
- 最好是先删除token,这样即使服务调用失败,也不会造成什么损失
- 验证完成之后,是先删除token再执行业务逻辑,还是先执行业务逻辑再删除呢?
- 如何解决呢?
- Token获取、比较、删除必须是原子性的,所以如果使用令牌机制,那么就可以选择redis中的lua脚本进行原子性操作,这样就不会出现上述问题了。
- 各种锁机制
- 数据库唯一索引约束
- redis防重
- 全局请求唯一ID
- Token(令牌)机制
多线程异步编排
初始化线程有哪几种方式?
有四种方式
- 继承Thread类
- 实现Runnable接口
- 实现callable接口
- 线程池
说说Runnable和Callable的区别
1)Runnable提供run方法,无法通过throws抛出异常,所有CheckedException必须在run方法内部处理。Callable提供call方法,直接抛出Exception异常。
2)Runnable的run方法无返回值,Callable的call方法提供返回值用来表示任务运行的结果
3)Runnable可以作为Thread构造器的参数,通过开启新的线程来执行,也可以通过线程池来执行。而Callable只能通过线程池执行。
- Callable任务通过线程池的submit方法提交。且submit方法返回Future对象,通过Future的get方法可以获得具体的计算结果。而且get是个阻塞的方法,如果任务未执行完,则一直等待。
Future和FutureTask的区别
- 对于Calleble来说,Future和FutureTask均可以用来获取任务执行结果,不过Future是个接口,FutureTask是Future的具体实现,而且FutureTask还间接实现了Runnable接口,也就是说FutureTask可以作为Runnable任务提交给线程池。
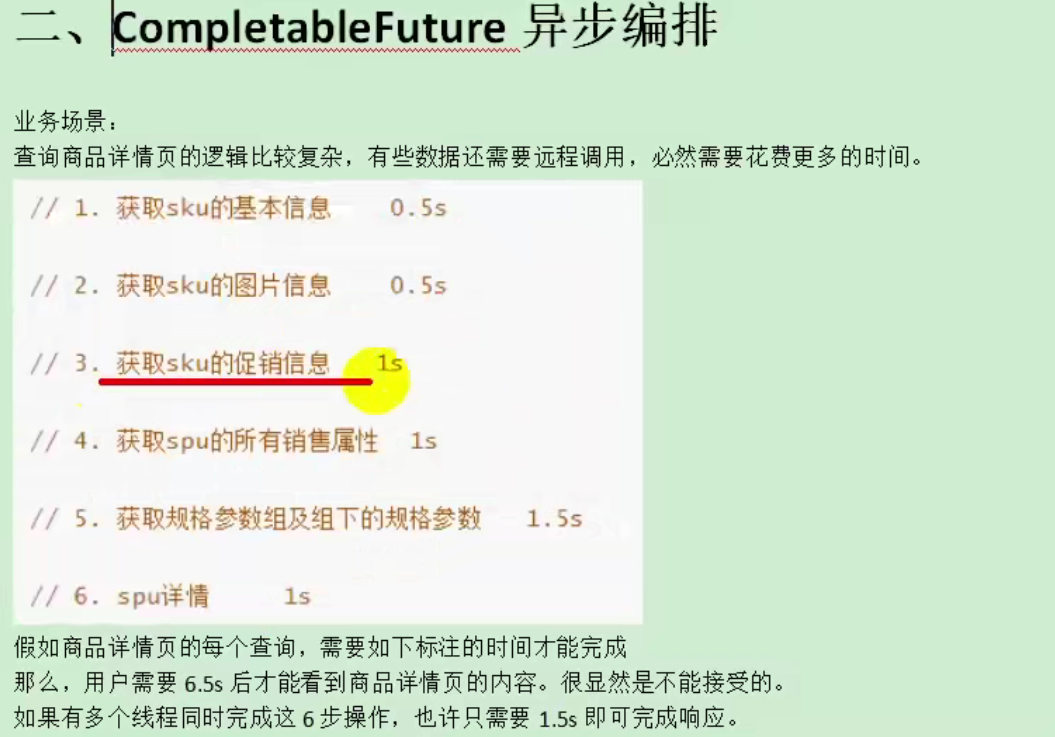
什么是异步任务?什么情况下使用异步任务?
不等任务执行完,直接执行下一个任务。
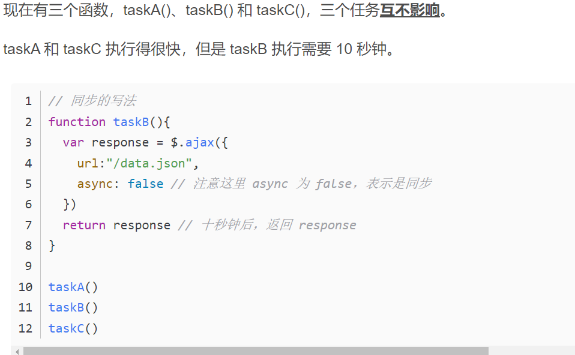
按照上面程序的执行顺序,如果是同步任务的话,会依次按照ABC进行执行,但是AC运行的比较快,如果等待B完成之后再完成AC,那么就会使整个程序运行的非常慢,因此使用异步任务,不用等B执行完成,直接运行AC,从而提高效率
线程池的七大参数知道吗?
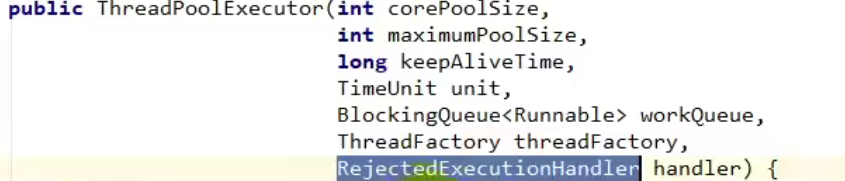
- 核心线程数:就是线程池创建的时候,里面就有的线程数,称为核心线程数
- 最大线程数:如果此时阻塞队列满了,核心线程全部都在运行,那么就会开始最大线程数来执行任务
- 存活时间:当开启了最大线程来完成了自己的任务的时候,并且任务执行完了,此时除了核心线程外,其他的额外线程就会在规定的时间里进行销毁
- 时间单位:存活时间的单位
- 阻塞队列:当线程都在运行,此时还有任务进来的时候,任务不会被直接,而是加入到阻塞队列中
- 线程工厂:指定创建线程的工厂
- 饱和策略:当开启了最大线程数,且阻塞队列也满了,但是现在还有任务正在加入,那么就会执行饱和策略,默认的饱和策略就是拒绝策略
- Abort策略:默认策略,新任务提交时直接抛出未检查的异常RejectedExecutionException,该异常可由调用者捕获。
- CallerRuns策略:为调节机制,既不抛弃任务也不抛出异常,而是将某些任务回退到调用者。不会在线程池的线程中执行新的任务,而是在调用exector的线程中运行新的任务。
- Discard策略:新提交的任务被抛弃。
- DiscardOldest策略:队列的是“队头”的任务,然后尝试提交新的任务。(不适合工作队列为优先队列场景)
为什么使用线程池?

在业务中, 你是怎么使用多线程异步任务来完成的?
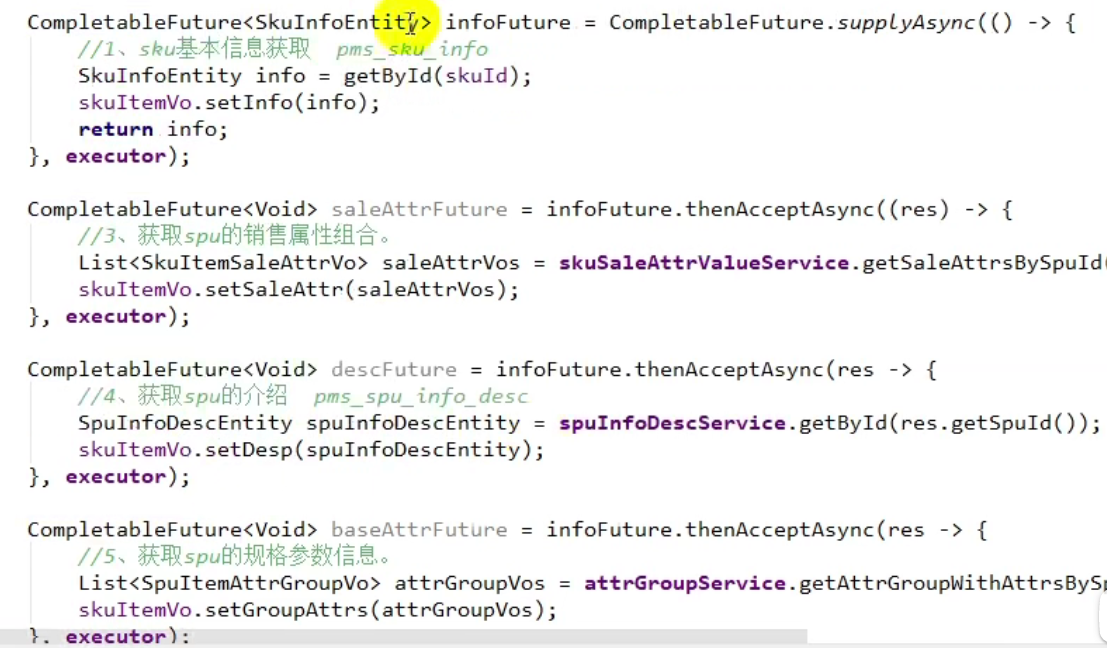
- 首先来看一下主要的方法



- 具体实现

分布式事务
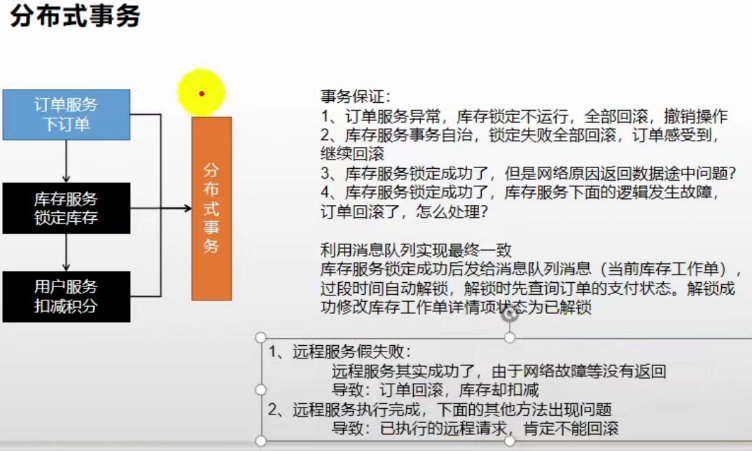
- 分布式事务会存在那些问题?
- 本地事务回滚,而远程服务不回滚
- 怎么解决?
- CAP定理
- 面临问题
现在互联网的集群规模越来越大,如果保证一致性,那么就要舍弃可用性,但是因为网络原因,或者节点故障而导致服务调用失败是常态,所以如果要保证可用性,就只能舍弃C而保证AP - BASE理论
- BASE理论是对CAP的一种延伸,意思就是即使无法做到强一致性,也可以做到弱一致性(最终一致性)
- 使用Seata解决分布式事务

消息队列
消息队列的应用场景
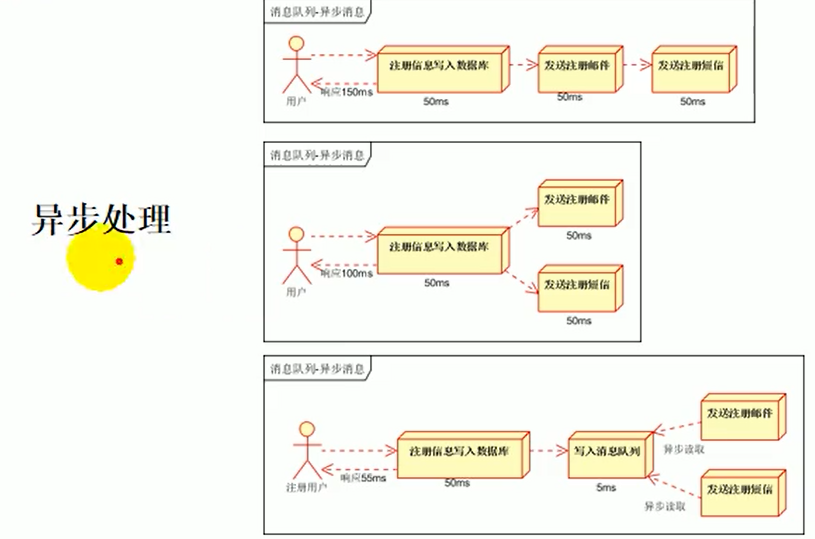
异步处理:比如一个注册功能,在注册的时候会首先将注册信息写入数据库,然后后面可能还需要发送邮件,发送信息等操作,这一系列操作都完成之后,才可以算真正的注册成功,但是这样非常的耗时,因此可以采用消息队列进行异步处理,也就是将用户的注册请求保存在消息队列中,然后直接让消息队列进行后续的异步处理逻辑
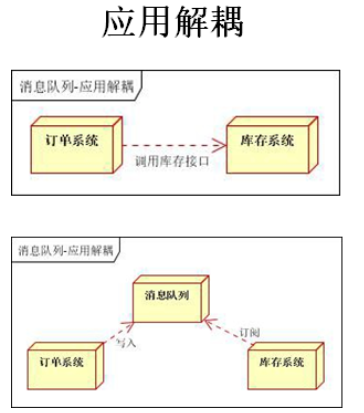
应用解耦:比如现在有两个微服务,他们之间需要一起调用实现一组操作,这个时候,可以通过消息中间件将他们分开,也就是解耦,让后面的服务不再依赖前面的服务,前面服务只需要将请求和数据存到消息队列中,而后面的服务只需要取出这些请求和数据进行相应的处理即可
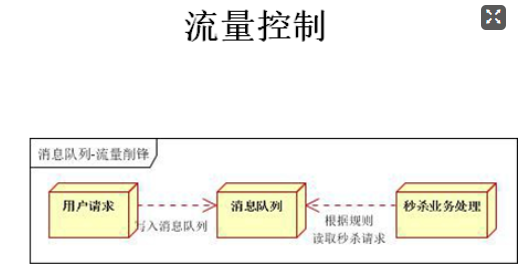
流量控制:例如现在一个系统是百万级并发的秒杀系统,那么这时候可能会出现每秒百万的请求进来,这时候即使服务器能承受的了这么多的请求,但是等待处理的话,后续还有请求进来,将会一直阻塞,然后系统会崩溃,这时候就可以通过消息队列将这些请求全部存储起来,这样将请求的后续操作慢慢进行,就不会导致服务器崩溃的情况了。
消息队列的定义

RabbitMQ的概念:
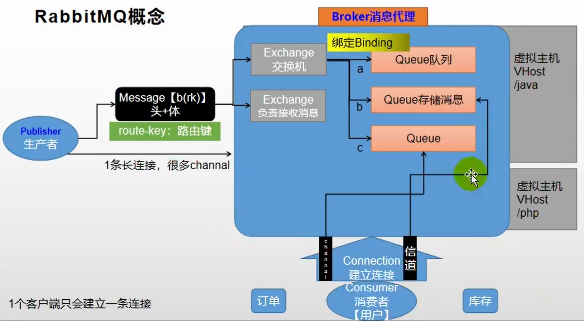
- 首先会有一个生产者来生产消息
- 消息是由消息头和消息体组成的,这其中消息头中有一个重要属性:Route-Key:路由键
- 交换机用来接收生产者生产的消息的,并将消息路由给服务器中的队列
- Broker消息中间键的服务器
- Queue消息队列,用于存储消息的
- VHost虚拟主机,主机之间互相隔离,互不影响
- Consumer消费者
具体工作流程:
首先生产者生产信息,然后将这些信息发送到消息服务器中,服务器会根据消息找到指定的交换机,然后交换机会通过路由键找到指定的队列,通过交换机与队列的绑定关系,将信息发送到队列中,然后由消费者通过与服务器建立连接,通过信道进行信息的传输
交换机类型



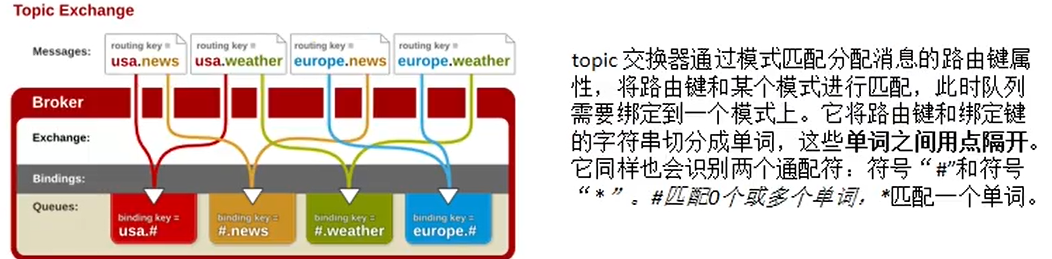
消息确认机制

p->b

e->q

q->c

延时队列
- 使用场景
- 下单成功之后,但是一直没有完成支付,那么在规定的时间内,如果一直没完成,那么时间结束,就会自动关单,并且将锁定的库存释放
- 使用场景



